Methods for evaluating Innovation from Ideas to Startups
The evaluation step of an innovation scouting process is the most time and resource consuming. A saying goes “ideas are worthless, execution is everything”. While the core message is that a not executed idea cannot result in value is true, the blanket statement that ideas are worthless distracts from a fact. The value in the idea is unearthed by executing it. The idea itself is a necessary precondition, but not sufficient for value creation. The execution must follow to turn the raw material into diamonds.
So investing early on in an idea with potential often results in higher returns than at a later stage where some of the risk has been mitigated, others have recognized the hidden value and the diamond is already on the horizon.
Evaluations are mostly seen as risk mitigation for investing resources into innovations. But they should also be seen as the opportunity to “get in” at the ground floor and be an early mover when none of your competitors has even realized a change is coming.
Benefits of structured evaluation of innovators
Evaluation is a trade-off between the resources invested to make a decision and the consequences of that decision. Both false positives (i.e. decision to invest further resources into an innovation that turns out to be a failure) and false negative (i.e. decision to pass on an innovation that turns out to be successful) are costly. Add to that the notion that 95% of innovations fail [2] and the need for a repeatable and improvable approach for evaluating innovation becomes apparent.
“We often find several purposes for evaluating innovation. The main purposes though, are to study and communicate the value, the innovation has created. At the same time, the evaluation is also used as a progress and management tool. The key ingredients here are systematic data collection and measurement.”
National Centre for Public Sector Innovation Denmark (COI)
Does this mean that gut feelings or anecdotal observations must give way to purely evidence based methods? Absolutely not. Structure can be established in any evaluation method with the goal of documenting the result. Structure does not imply quantitative methods, but rather repeatable methods. The accuracy of a subjective evaluation by an individual domain expert can be tremendous, but it always includes bias. Oftentimes inertia to change is present and other factors that reduce it’s accuracy. The only way to identify these issues though is to tie the original evaluation to the result which can be months, years or decades later. Structured documentation leads to both transparency and accountability in the evaluation process.

Categories of Innovation Evaluation
The term evaluation applies to a vast array of methods from evidence-based financial methods, or pattern matching, to purely experience based gut-feeling. Each of these has it’s place in the innovation scouting process at different times, but there are four distinct categories.
Automated Innovation Evaluation Methods
In early stages of your innovation funnel where the quantity of ideas is high the choice falls on highly automate-able (i.e. low investment) evaluations. These can be as basic as a questionnaire that doesn’t let the innovator continue if certain preconditions aren’t met (e.g. in government based funding schemes it is often a requirement to be an established company in that country) or an innovation scout that determines the innovation it outside of the predetermined scope they are working off just by using a checklist.
Often times these filters act as “gates”. They do not allow the innovator to enter your realm. But in innovation scouting it can be useful to establish the innovator as a lead anyway. After all that same innovator may not qualify at the moment, but your search scope may change or the innovation could pivot and therefore keeping an eye out for previously disqualified innovations is a useful tool for the innovation scout.
Typical evaluation methods in this category:
- Automated questionnaires
- Accounting integration (e.g. cannot surpass a certain revenue point)
- Government reports (digital tax returns)
Typically these evaluation methods are used in:
- Industry events by the innovation scout collecting leads
- Hackathons with specific topics during the ideation phase
- Investment or grant programs before submission
Fast Innovation Evaluation Methods
Automatic evaluations rely on hard metrics whereas most innovation requires an analysis of the qualitative substance. When large number of innovations require evaluation and where there is little negative impact for a bad decision a trade-off on the quality of the judgement is made in favor of speed.
One approach is to use the “wisdom of the crowds”. This term coined by Surowiecki [4] denotes the rule of polling large audiences often times averages out any biases present in the individual members. You see this approach applied at startup events, idea and pitch competitions where the audience casts a vote to determine a winner.
In a similar vane startup events can employ jury or expert panels during pitching competitions to score the innovation potential. Where the audience is often only asked to choose their favorite, the panel will usually judge a handful of criteria on a quantitative scale but then follow-up in a round of discussions later to determine the ultimate winner. (See our follow-up article on evaluating startups and innovations using scorecards.)
Although often times the quantitative result is the overridden by a discussion of the jury or experts. There are valid for this as these predetermined scorecards do not always cover the breadth of innovation correctly. Unfortunately discussions also have the potential to let the “loudest person in the room” get their way. Therefore an override-able quantitative approach should be audited by an independent party depending on the implications of the decision being made.
In any case the organizer should question the jury and experts as to which factors were missing from the scorecard. Especially if it is determined that a missing factor caused a different winner to be chosen.
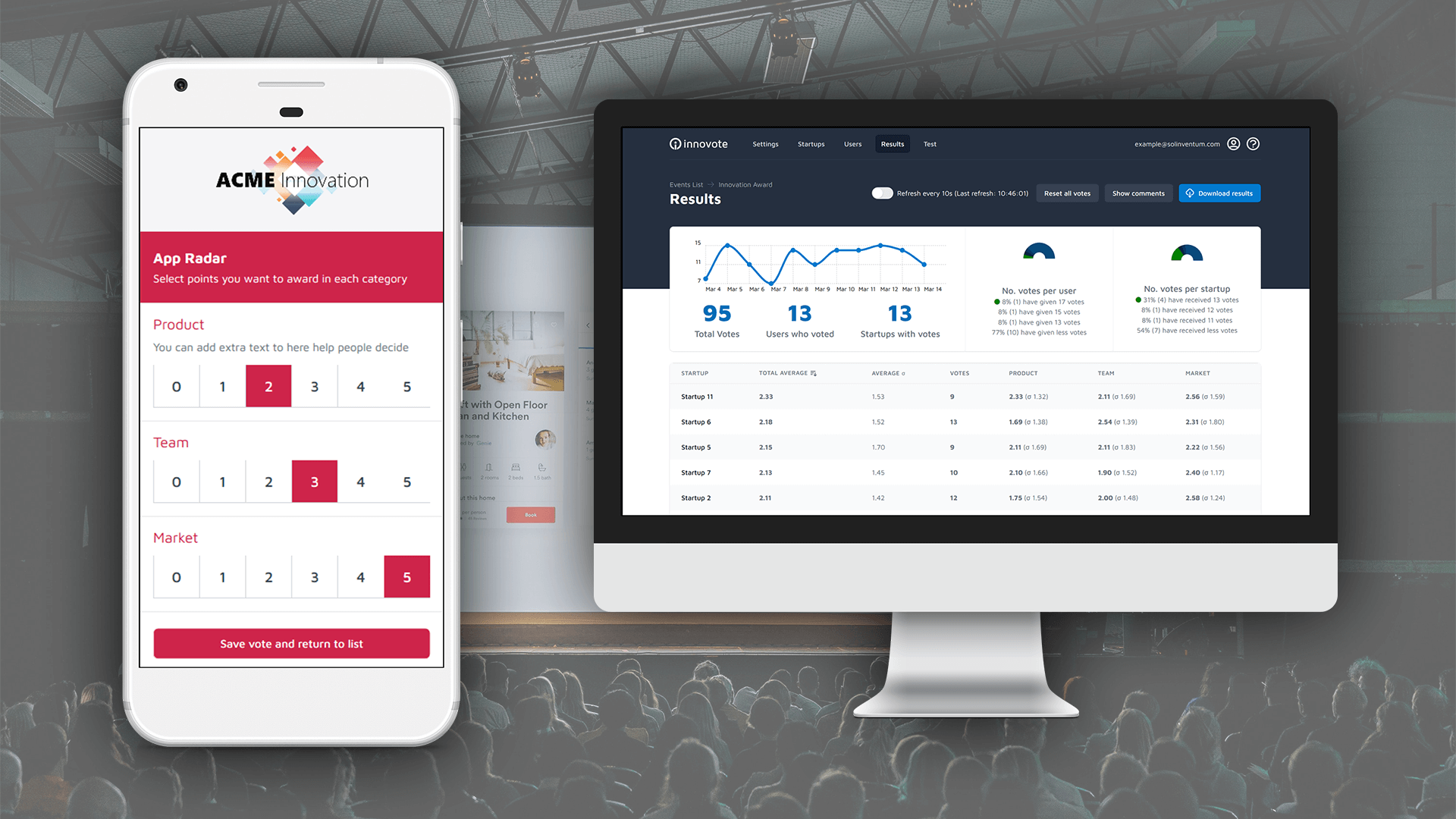
Typical evaluation methods in this category:
- Real-time Jury / Expert Panels using Scorecards
- Crowd-sourced / Audience ratings using Winner Voting
Typically these evaluation methods are used in:
- Startup events, pitch and idea competitions
- Hackathons, Meetups, Unconferences
- High level evaluation at the beginning of an innovation funnel
Analytical Innovation Evaluation Methods
The higher the potential impact of the decisions you are making based on an evaluation, the higher the need for more analytical methods to be applied. This will be the bulk of evaluations performed in an innovation scouting process by the innovation knowledge network.
Each group of people in the knowledge network should be involved in creating the detailed scorecard and include criteria that correspond to their expertise.
- Domain experts will include criteria for evaluating the technical or production feasibility, emerging market trends, innovative-ness etc, but also industry experience of the innovation team (or single innovator).
- Business experts will look at the business model in general, if all parts of the supply chain are covered, which markets are being serviced and at what cost. A high level view on the financials is also often useful, but more in terms of a trend analysis of a short window (3, 6, or 12 months).
- Innovation scouts and managers will include criteria such as team skills, distribution or lack of competencies and roles in the innovation entity, uniqueness of their idea and approach with respect to other innovations in the industry.
Some criteria of one group may overlap with those of another. In this case it is important to identify if the same value is being measured and that is is not simply a naming issue. For example the term “team experience” can mean industry or professional experience for the domain experts but entrepreneurial experience for the innovation experts – two very different skill sets.
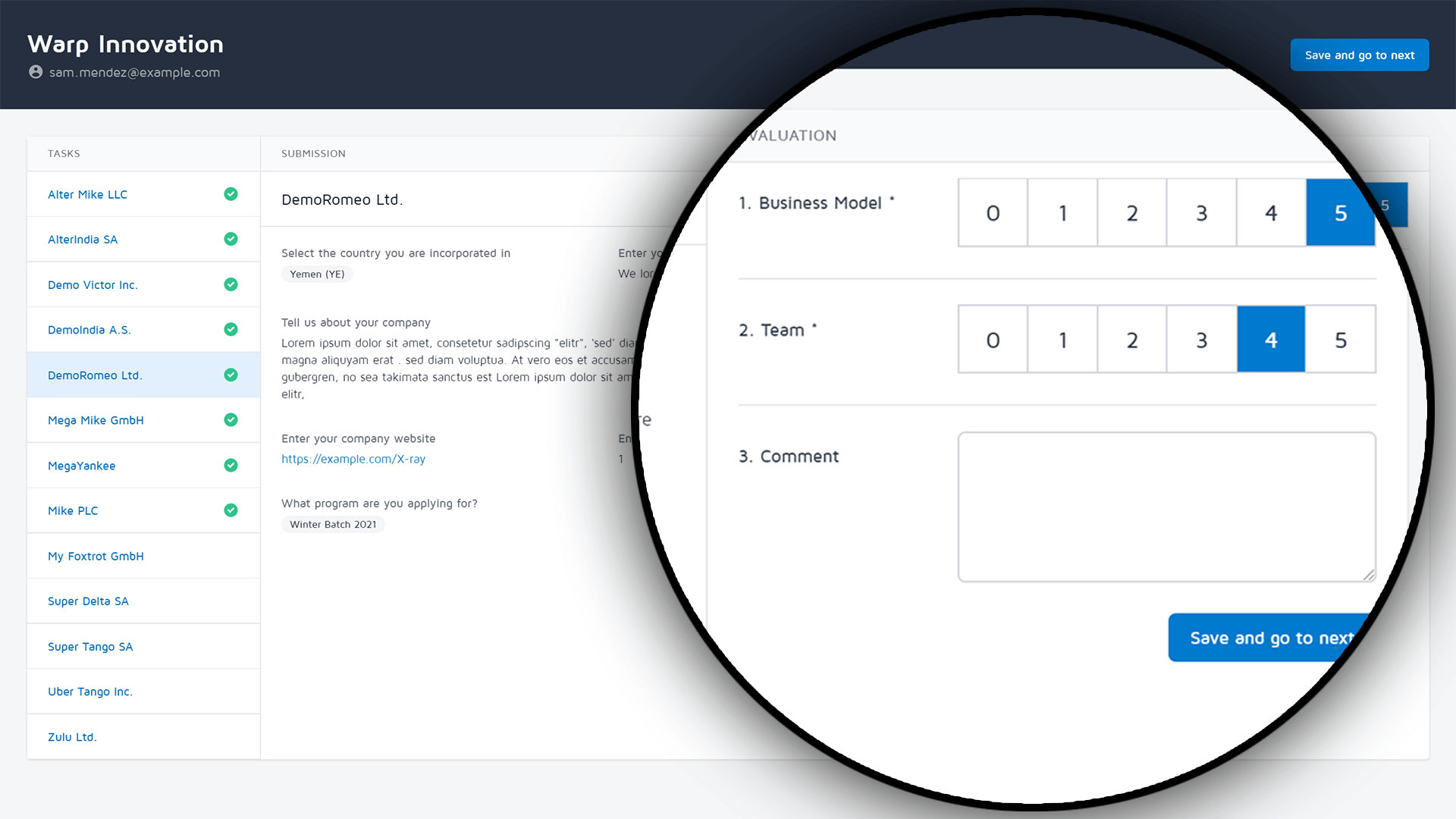
Typical evaluation methods in this category:
- Scorecards
- Qualitative summary judgement
Typically these evaluation methods are used in:
- Innovation Scouting Funnels
- Government funds to a certain degree
- Accelerator programs
Formal Innovation Evaluation Methods
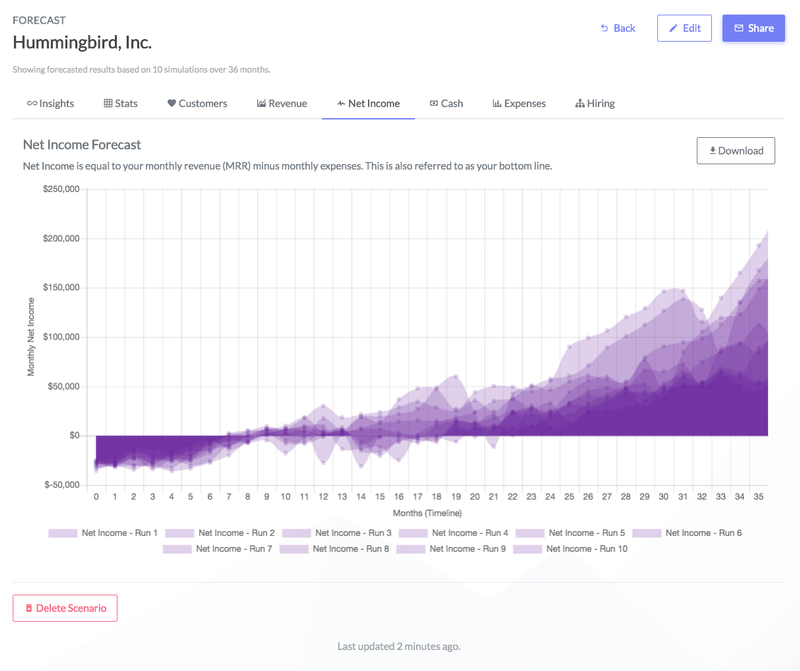
If the innovation is considered later stage (i.e. has reached product market fit and gained some traction) then using any available financial data to set a valuation of the innovation, innovator or company in question is possible. Both early (angel) and later (venture capital) investors will use a variety of calculation models to estimate the worth of a company before trying to invest.
The reliability of these calculation models can be improved through the use of statistical simulations that create a model from the base financial data and automate the introduction of certain events (investment, hires, repeating trends) into a future projection of the KPIs.
Typical evaluation methods in this category:
- Financial methods: First Chicago, Venture Capital Method, Discounted Cash Flow
- Traction and/or Market Analysis
- Simulations
Typically these evaluation methods are used in:
- Angel, Accelerator or Venture Capital Investments
- Merger and Acquisitions
How to structure innovation evaluation?
Many of the mentioned methods can and should be performed in a structured fashion to achieve transparency and repeatability and often even comparability. Let’s look at some methods in detail.
Questionnaire Automation
The most trivial family of methods to document are questionnaire automations. By definition the questionnaire schema is stored and can be pulled up at any time. Note though that versioning is important where questionnaires are reused. If possible the innovation scouting system that offers application questionnaires should be able to clone previous questionnaires for reuse which allows you to re-visit past questionnaire versions instead of simply updating one master version (which would result in not knowing which automatic filters were applied in the previous instances).
Scorecards (Audience, Jury and Experts Panels)
Even a single audience question regarding which innovation is their favorite can be considered a scorecard. But as the complexity of these questions grow you arrive at a structure you would probably recognize as a typical score card.
Using digital tools for innovation evaluation you have the automatic benefits of knowing which questions were asked, who answered them in what way, which weighting factors were employed and can reproduce the result at any time in the future.
More importantly over time you can analyse which variables had the best predictive evaluation result and not only change future evaluations but also course correct the innovation evaluation that are more recent with pending decisions regarding new and follow-on investments.
Formal methods
This family of evaluations is structured by default but there are few things to be mindful of.
Algorithms may change over time, so a versioned history is necessary to fulfill the requirement of transparency. Similarly all inputs to the algorithm must be documented. This obviously includes the data provided by the innovator but also any parameter variables that may have been set and any context data that was used (for example historical market data or a machine learning training data set). Only if all inputs are available at a later stage can the algorithm produce the same output and if required be changed to adapt to new learning over time.
Note: Some algorithms (e.g. Monte Carlo simulations) may be non deterministic and include random elements. While these are powerful tools they are also hard to document. It cannot be expected that the same simulation even if run in parallel produces the same exact output give the same inputs, but rather the output range (a statistical set of probabilities) should be reproduce-able.
Further reading and References
- National Center for Public Sector Innovation Denmark. (n.d.). Evaluating innovation. Center for Offentlig Innovation. https://www.coi.dk/en/what-we-do/evaluating-innovation/
- Carmen Nobel. (2011, February 14). Clay Christensen’s milkshake marketing. HBS Working Knowledge. https://hbswk.hbs.edu/item/clay-christensens-milkshake-marketing
- Merz, Alexander. (2018). Mechanisms to Select Ideas in Crowdsourced Innovation Contests – A Systematic Literature Review and Research Agenda.
- Surowiecki, J. (2005). The wisdom of crowds. Anchor.